―文献名―
Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum
J.W.Ayers et al., JAMA Intern Med. 2023;183(6):589-596. doi:10.1001/jamainternmed.2023.1838
―要約―
Introduction:
・COVID-19流行下でVirtual careの導入が早まり、患者からの電子メッセージは1.6倍に増加した。それに伴い医師の負担が増加、燃え尽き症候群のリスクも向上すると考えられる
・医師と患者の電子メッセージでのやり取りの負担を減らす目的で、AIチャットボットの活用は期待されている
・今回、2022年11月にリリースされたAIチャットボットアシスタント(ChatGPT)を用いて、患者の質問に対する共感的で高品質な回答の能力を評価した
Method:
・この横断的研究では、公開されたソーシャルメディアフォーラム(Redditのr/AskDocs)からの質問データベースを使用し、2022年10月に医師が回答した195の質問を無作為に抽出
・一人の医師が複数回回答した場合は、最初の回答のみを考慮したが、その後の医師の回答を除外するか含めるかの判断にかかわらず、結果はほぼ同じであった
・チャットボットの回答は、2022年12月22日と23日に新しいセッションで元の質問を入力することで生成され、元の質問と匿名化されランダムに並べられた医師とチャットボットの回答は3回にわたり評価された。
・評価者は小児科、老年科、内科、腫瘍科、感染症科、 および予防医学に従事する免許を持つ医療専門家のチ
ーム
・評価は、「どの回答がより良かったか」の選択と「提供された情報の質」(非常に悪い、悪い、許容範囲、良い、非常に良い)、「提供された共感やベッドサイド・マナー」(共感できない、少し共感できる、適度に共感できる、共感できる、非常に共感できる)の評価を含んでいた。評価は1~5の5段階で行われ、結果はチャットボットと医師で比較された。
<統計学的手法>
・私たちは、調査した各交換について評価者間でスコアを平均化する、群衆(またはアンサンブル)スコアリング戦略に依存した
・医師とチャットボットの回答の単語数を比較し、チャットボットが好まれた回答の割合を報告した。両側t検定を用いて、医師の回答とチャットボットの回答の平均品質と共感スコアを比較した。さらに、適切でないなどの重要な閾値を上回ったり下回ったりする回答の割合を比較し、チャットボットと医師の回答を比較して有病比を計算した
・また、質と共感のスコア間のピアソン相関も報告した。
・臨床での患者の質問はオンラインフォーラムに投稿されたものよりも長いかもしれないと仮定して、我々はまた、医師が作成した長い返信(中央値または75パーセンタイル以上の長さのものを含む)にデータをサブセットすることで、評価者の嗜好やチャットボットの回答に対する質や共感の評価がどの程度変化するかを評価した。
Result:
・195の質問と回答のうち、評価者は585の評価(195×3)の78.6%(95%CI、75.0%-81.8%)で医師の回答よりもチャットボットの回答を好んだ。
・医師の回答の平均値(IQR)はチャットボットの回答よりも有意に短かった(52 [17-62] words vs 211 [168-245] words; t =25.4;P < 0.001)。
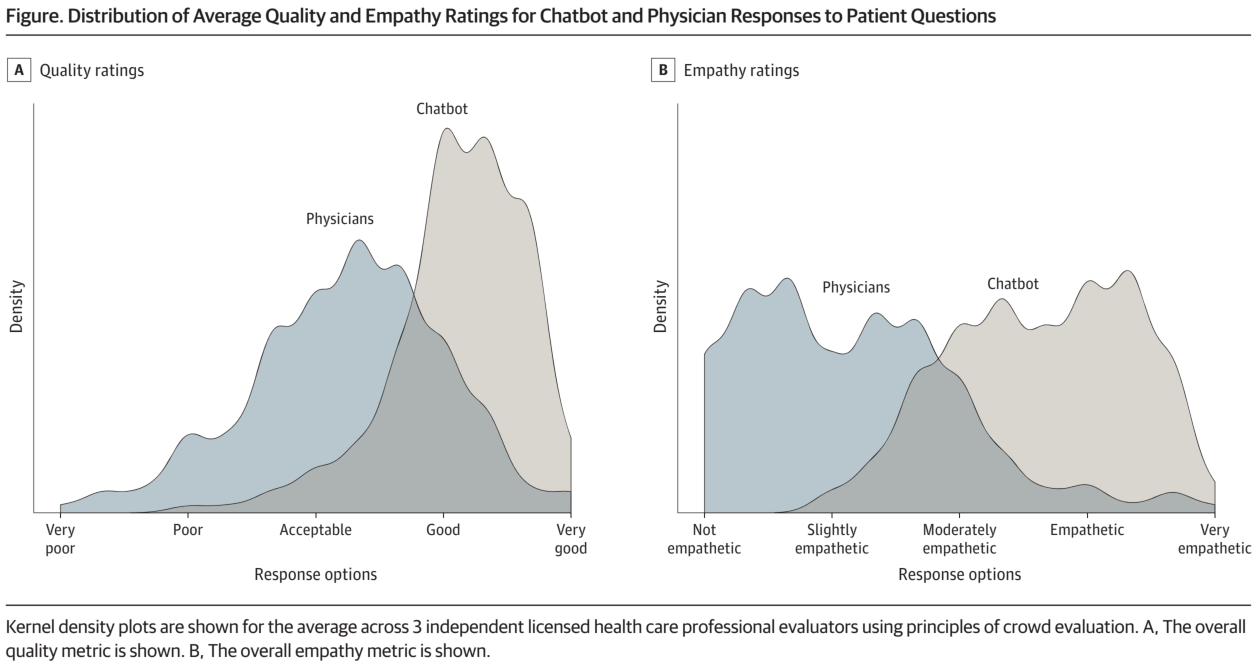
・チャットボットの回答は医師の回答よりも有意に質が高いと評価された(t = 13.3; P < .001)。例えば、「良い」または「非常に良い」と評価された回答の割合は、医師よりもチャットボットの方が高かった(チャットボット:78.5%、95%CI、72.3%-84.1%;医師:22.1%、95%CI、16.4%-28.2%)。これは、チャットボットの良質または非常に良質な回答の有病率が3.6倍高いことに相当する
・チャットボットの回答はまた、医師の回答よりも有意に共感的と評価された(t =18.9; P < 0.001)。共感的または非常に共感的(4)と評価された回答の割合は、医師よりもチャットボットの方が高かった(医師: 4.6%, 95% CI, 2.1%-7.7%; chatbot: 45.1%、95% CI、 38.5%-51.8%; 医師は 4.6%、95% CI、2.1%-7.7%)。これは、チャットボットの方が共感的または非常に共感的な回答の有病率が9.8倍高かったことを示している。
Discussion
・SNSの質問を用いているので、臨床現場における医師患者間のやりとりを十分に反映していない。特に、今回は単回の返答のみを扱っているが、本来臨床現場では複数回のやりとりを通じて医師患者関係を築いていくものである
・医師の回答とChatbotの回答の相乗効果については検討できていない
・臨床上でよくあるより詳細なやり取り(予約やリフィル処方、特定の検査結果の説明、個別の治療プラン、予後、等)については評価できていない
・質や共感性の評価方法はこれまでに確立されたものではない
・本研究の評価者は、回答の出所や初期結果について盲検化されていたにもかかわらず、共著者でもあったため、評価に偏りがあった可能性がある
・チャットボットの回答の長さが、より大きな共感と誤って関連づけられた可能性がある
・評価者は、医師またはチャットボットの回答の正確さや捏造された情報について、独立した具体的な評価を行わなかった
【開催日】2024年1月10日(水)